Overview
An intensive algorithmic research project focused on stabilizing and optimizing a Double Deep Q-Network (DDQN) agent to solve the CartPole control problem by systematically tuning hyperparameters[cite: 281, 282, 318].
Key Highlights
1. Problem
While Deep Reinforcement Learning (DRL) is a powerful tool for robotic control, models like Q-Networks often suffer from training instability and overestimation[cite: 296, 297]. Achieving fast, reliable, and consistent convergence requires rigorous tuning of the algorithm’s hyperparameters, which is traditionally a highly heuristic and time-consuming process.
2. Methodology & Optimization
Implemented a DDQN algorithm using Keras and the OpenAI Gym CartPole environment[cite: 313]. To maximize learning efficiency, an extensive A/B testing framework was constructed to systematically tune 11 distinct variables—including learning rate, epsilon decay, network depth, and activation functions[cite: 282, 321, 429]. Each variation was trained for 100 episodes to evaluate its impact on mean scores and standard deviation[cite: 282, 283].
*Fig. 1: CartPole Simulation Environment* The OpenAI Gym CartPole environment where the DDQN agent was trained to balance the pole by applying lateral forces to the cart.
3. Performance
Successfully identified the optimal combination of hyperparameters that maximized reward acquisition[cite: 314, 434]. The finely tuned architecture—utilizing 4 hidden layers, 24 nodes, a batch size of 32, the Nadam optimizer, a learning rate of 0.001, and the ReLU activation function—demonstrated highly stable and efficient policy learning compared to the baseline[cite: 527].
4. Validation
Evaluated the optimized DDQN model against the default model over 1,000 episodes, tracking the number of trials required to achieve the success threshold (an average score > 195 over the last 100 episodes)[cite: 451, 455]. The default model required an average of 549.6 episodes to pass and failed to converge 40% of the time[cite: 457, 458]. In contrast, the optimized model achieved the threshold in just 151.8 episodes on average across all trials, representing a ~72% improvement in learning efficiency[cite: 458, 788].
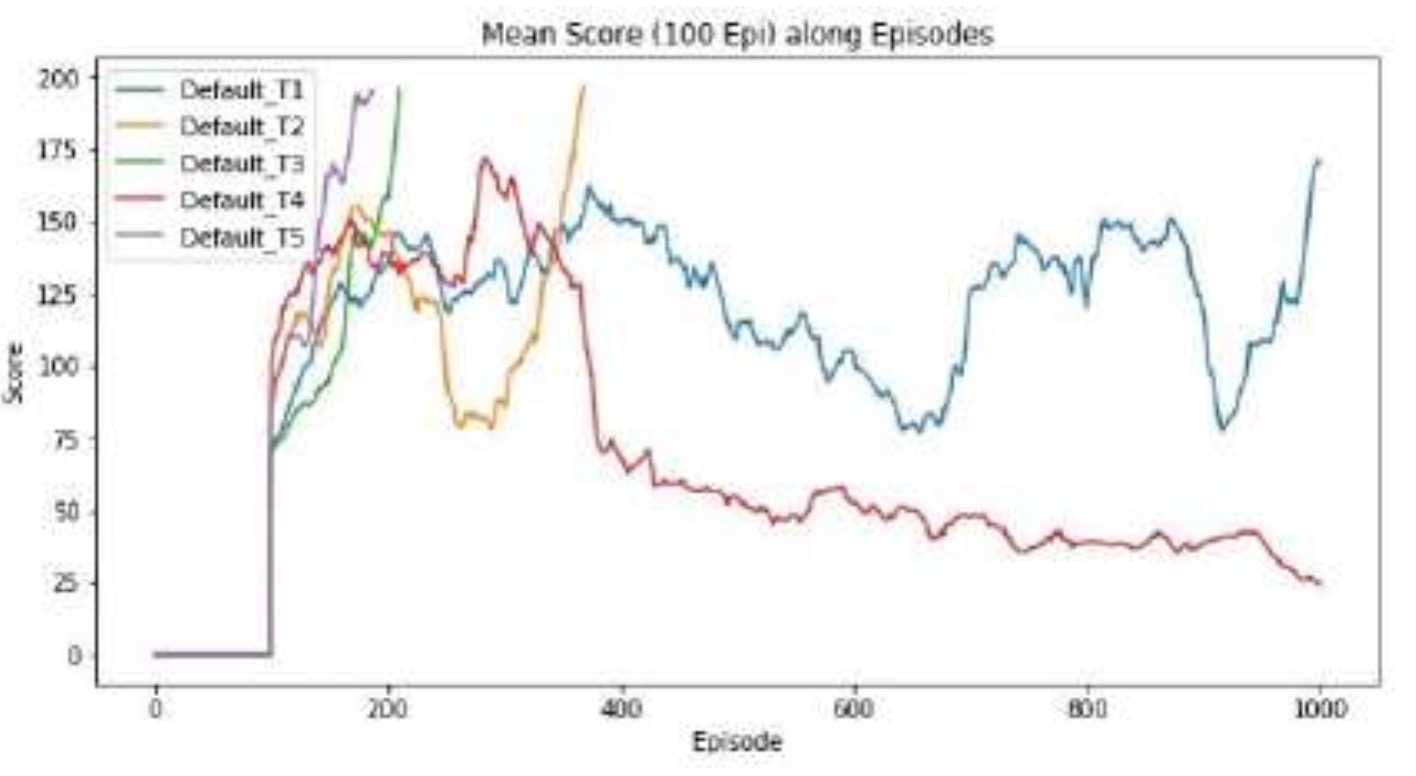
*Fig. 2: Default Model Learning Curve* Graph of 1000 running episodes using the default parameters. Note the instability and failure of two trials to reach the threshold.
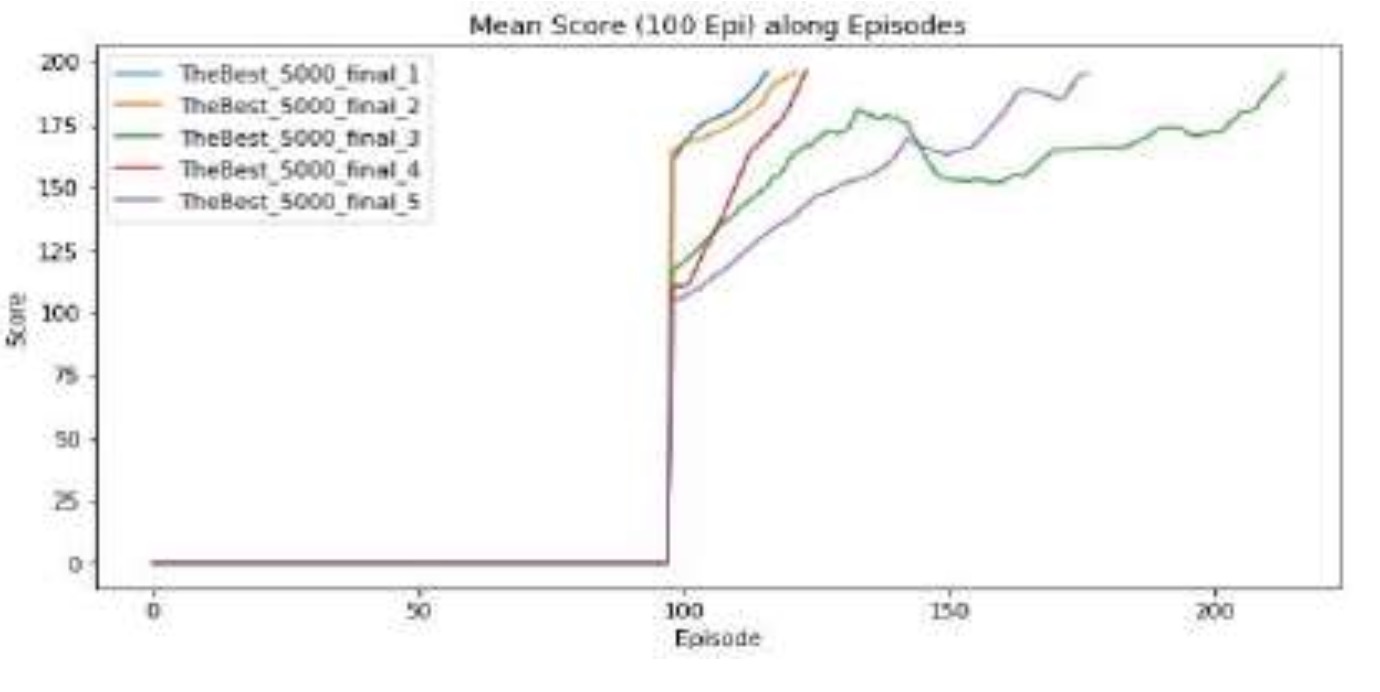
*Fig. 3: Optimized Model Learning Curve* Graph of 1000 running episodes using the tuned hyperparameters. Convergence is much faster, achieving stability in an average of 151.8 episodes.